
Introduction
In the realm of data analysis, dashboarding, and optimization, the concept of data windowing emerges as a powerful tool. It involves aggregating an ordered set of elements into a cohesive structure. This article dives into the intricacies of implementing data windowing in PostgreSQL, a robust database management system, without writing any additional lines of code. We'll explore this through the lens of the cryptocurrency market, specifically using OHLC (Open, High, Low, Close) data from the Binance platform.
Understanding Data Windowing in PostgreSQL
Data windowing is not just a mere function; it's a way to glean insights from data by aggregating and organizing it based on specific criteria. PostgreSQL, with its advanced SQL capabilities, allows users to execute this process efficiently. In our example, we focus on OHLC crypto market data, captured hourly on Binance via API. The data is organized by hour and currency, and our task is to create a grouping structure based on the “open_time” field.
Practical Example: Grouping OHLC Data
Let’s delve into a concrete example to illustrate the power of PostgreSQL in handling this task.
Step 1: Generating Group Numbers
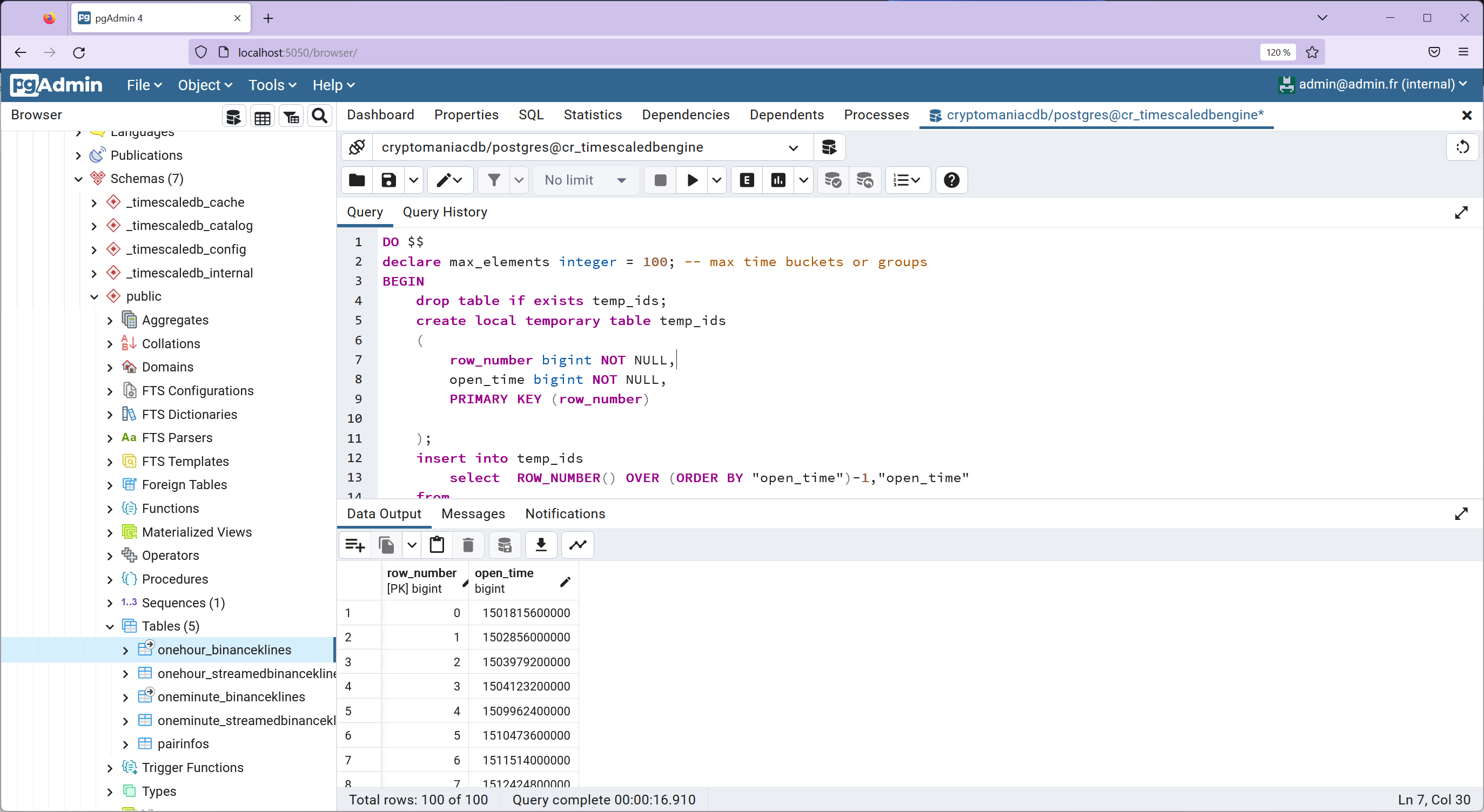
First, we need to generate group numbers for our data. This process involves creating a temporary table, temp_ids, to store these groups. The groups are randomly selected using the order by random() clause. Here's the SQL code to accomplish this:
DO $$
declare max_elements integer = 100; -- max time buckets or groups
BEGIN
drop table if exists temp_ids;
create local temporary table temp_ids
(
row_number bigint NOT NULL,
open_time bigint NOT NULL,
PRIMARY KEY (row_number)
);
insert into temp_ids
select ROW_NUMBER() OVER (ORDER BY "open_time")-1,"open_time"
from
(
select "open_time"
from onehour_binanceklines
group by open_time
order by random()
limit max_elements
) dummy;
create index open_time_index on temp_ids (open_time);
END $$;
select * from temp_ids;
Step 2: Creating Sub-Group References
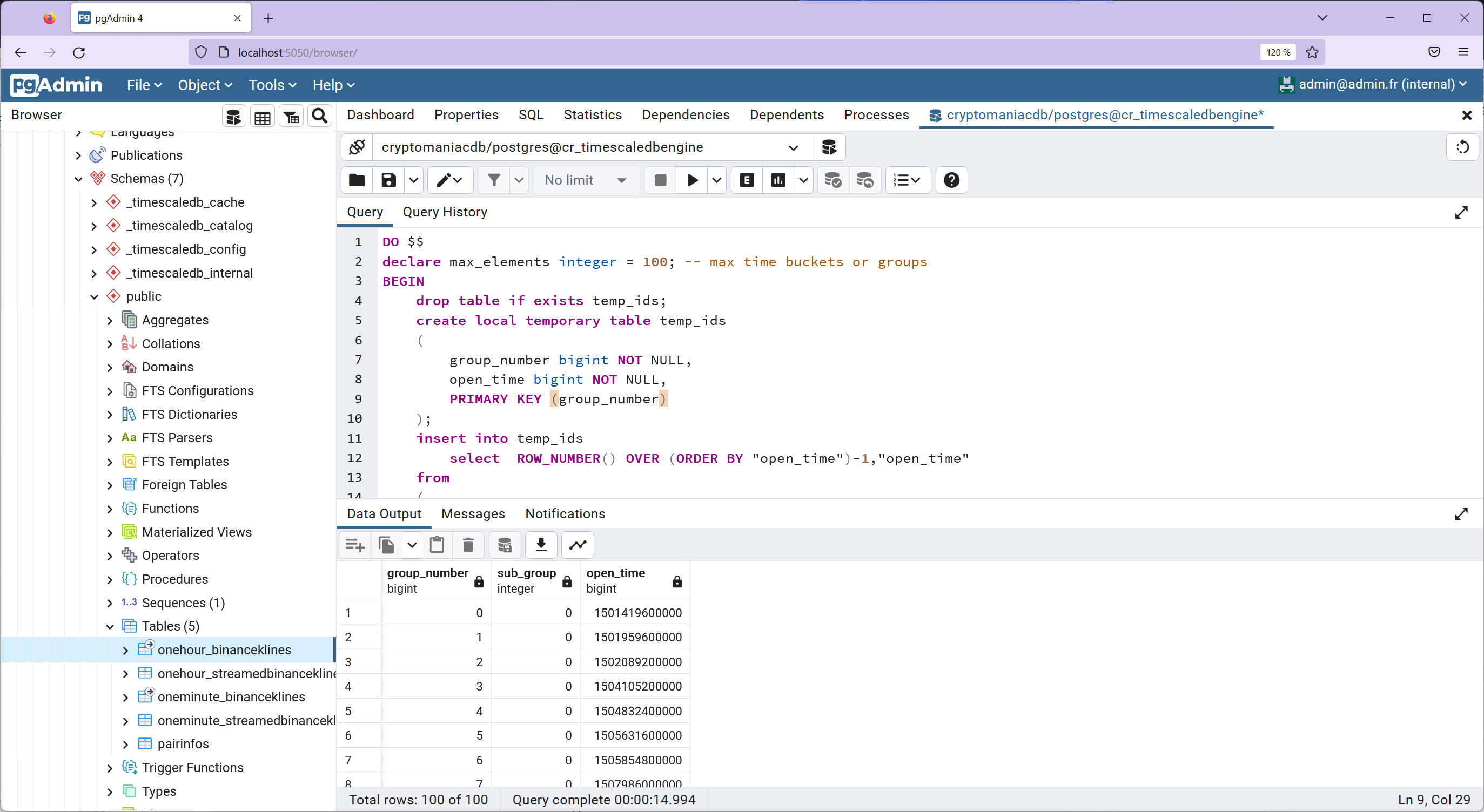
Next, we create the first sub-group references in a new temporary table, temp_results. This step involves inserting data into temp_results from temp_ids:
DO $$
declare max_elements integer = 100; -- max time buckets or groups
BEGIN
drop table if exists temp_ids;
create local temporary table temp_ids
(
group_number bigint NOT NULL,
open_time bigint NOT NULL,
PRIMARY KEY (group_number)
);
insert into temp_ids
select ROW_NUMBER() OVER (ORDER BY "open_time")-1,"open_time"
from
(
select "open_time"
from onehour_binanceklines
group by open_time
order by random()
limit max_elements
) dummy;
create index open_time_index on temp_ids (open_time);
drop table if exists temp_results;
create local temporary table temp_results
(
group_number bigint NOT NULL,
sub_group int NULL,
open_time bigint NOT NULL
);
insert into temp_results
select group_number,0,open_time from temp_ids;
END $$;
select * from temp_results;
Step 3: Generating Missing Sub-Group References
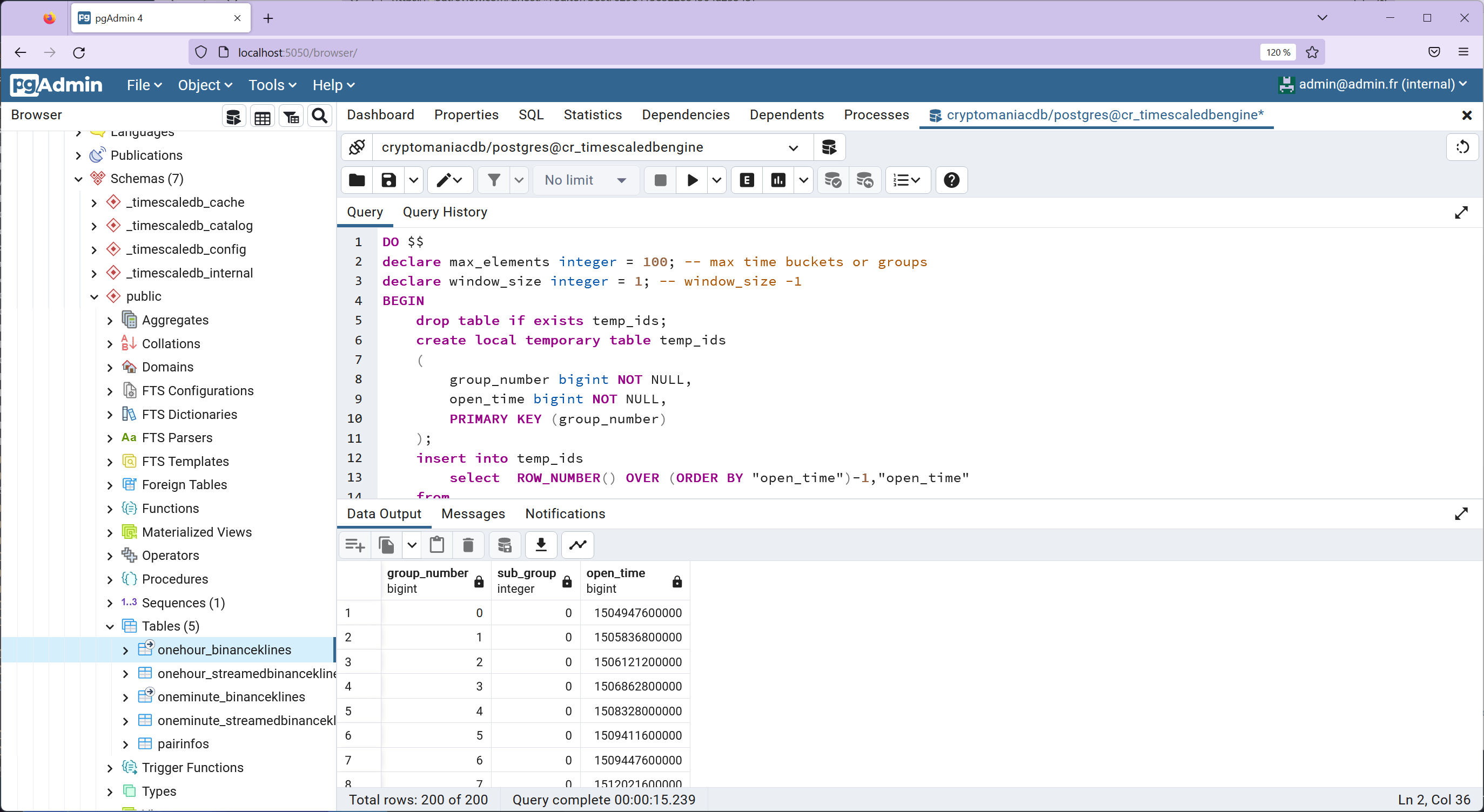
We then generate the missing sub-group references using the left outer join LATERAL clause. This step is crucial in ensuring that our windowing structure is complete:
DO $$
declare max_elements integer = 100; -- max time buckets or groups
declare window_size integer = 1; -- window_size -1
BEGIN
drop table if exists temp_ids;
create local temporary table temp_ids
(
group_number bigint NOT NULL,
open_time bigint NOT NULL,
PRIMARY KEY (group_number)
);
insert into temp_ids
select ROW_NUMBER() OVER (ORDER BY "open_time")-1,"open_time"
from
(
select "open_time"
from onehour_binanceklines
group by open_time
order by random()
limit max_elements
) dummy;
create index open_time_index on temp_ids (open_time);
drop table if exists temp_results;
create local temporary table temp_results
(
group_number bigint NOT NULL,
sub_group int NULL,
open_time bigint NOT NULL
);
insert into temp_results
select group_number,0,open_time from temp_ids;
if (window_size)>0 then
insert into temp_results
select tt.group_number,0,prev_row.open_time from temp_ids tt
left outer join LATERAL
(
select distinct oo.open_time
from onehour_binanceklines oo
where
(oo.open_time < tt.open_time)
order by oo.open_time desc
limit window_size
) prev_row on true;
end if;
END $$;
select * from temp_results;
Step 4: Renumbering Subgroups
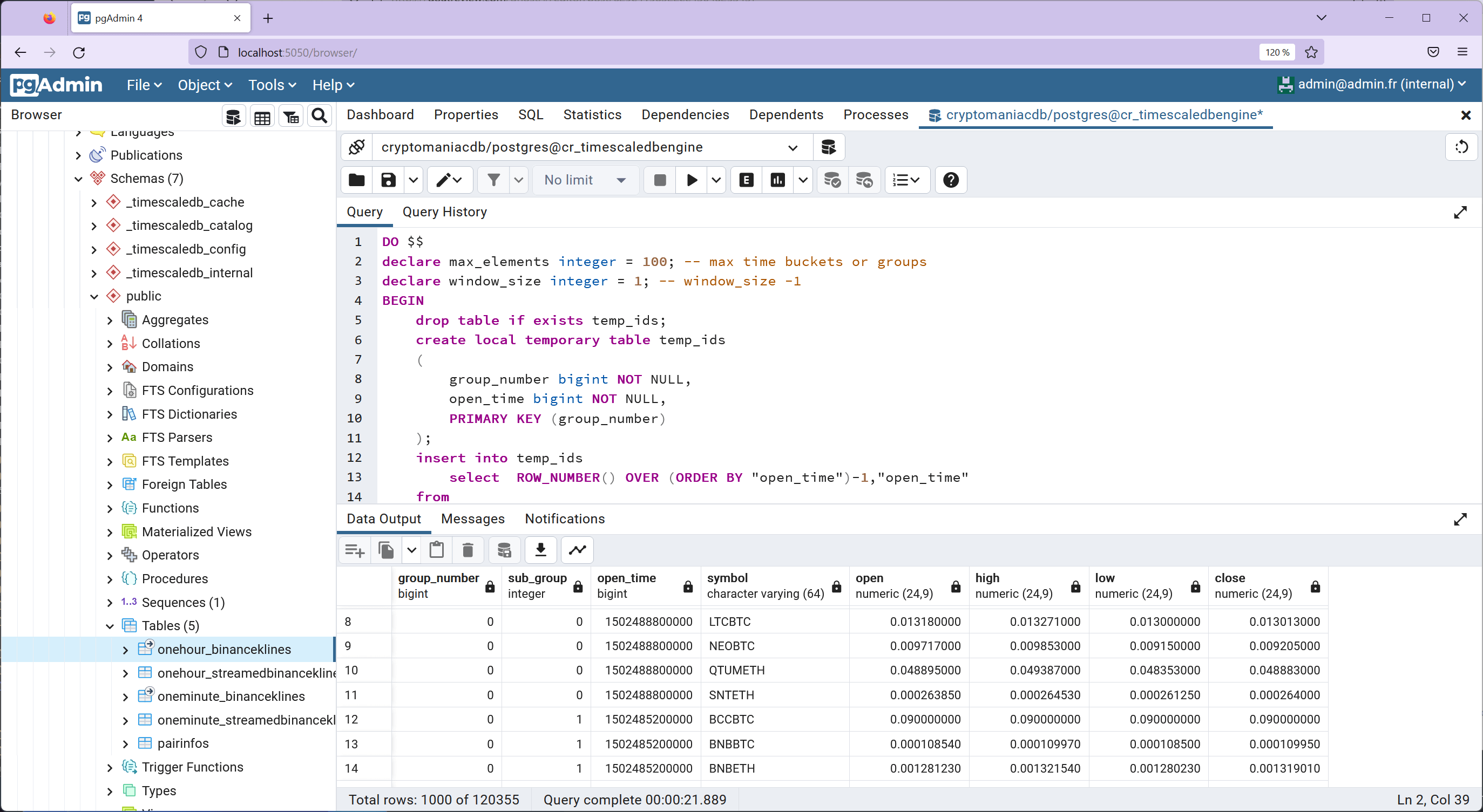
Finally, the subgroups are renumbered using the PARTITION BY clause. This renumbering is essential for organizing the data effectively:
DO $$
declare max_elements integer = 100; -- max time buckets or groups
declare window_size integer = 1; -- window_size -1
BEGIN
drop table if exists temp_ids;
create local temporary table temp_ids
(
group_number bigint NOT NULL,
open_time bigint NOT NULL,
PRIMARY KEY (group_number)
);
insert into temp_ids
select ROW_NUMBER() OVER (ORDER BY "open_time")-1,"open_time"
from
(
select "open_time"
from onehour_binanceklines
group by open_time
order by random()
limit max_elements
) dummy;
create index open_time_index on temp_ids (open_time);
drop table if exists temp_results;
create local temporary table temp_results
(
group_number bigint NOT NULL,
sub_group int NULL,
open_time bigint NOT NULL
);
insert into temp_results
select group_number,0,open_time from temp_ids;
if (window_size)>0 then
insert into temp_results
select tt.group_number,0,prev_row.open_time from temp_ids tt
left outer join LATERAL
(
select distinct oo.open_time
from onehour_binanceklines oo
where
(oo.open_time < tt.open_time)
order by oo.open_time desc
limit window_size
) prev_row on true;
end if;
create index group_number_open_time_index on temp_results (group_number,"open_time");
update temp_results
set sub_group=tt.sub_group
from
(
select "group_number","open_time",ROW_NUMBER() OVER (PARTITION BY "group_number" ORDER BY "group_number","open_time" desc )-1 sub_group from temp_results
) tt
where temp_results."group_number"=tt."group_number"
and temp_results."open_time"=tt."open_time";
END $$;
select tt."group_number",tt."sub_group",bk."open_time",pi."symbol",bk."open",bk."high",bk."low",bk."close" from temp_results tt
inner join onehour_binanceklines bk on (bk."open_time"=tt."open_time")
inner join pairinfos pi on (pi."id"=bk."pairinfo_id")
Conclusion
This article demonstrates the power and flexibility of PostgreSQL in handling complex data windowing operations. By leveraging SQL, we can efficiently group and analyze large datasets, as shown in our example with OHLC crypto market data. Remember, the key to mastering data windowing lies in understanding your data and the tools at your disposal.
Have a goat day 🐐
Join the conversation.